Fantastic Personas and Where to Find Them: Mapping the Geometry of Role Vectors in Activation Space
Hi everyone. MATS 9.0 is at an end, and my team’s research work on personas is done – “Fantastic Personas and Where to Find Them: Mapping the Geometry of Role Vectors in Activation Space”.
BLUF: We make contributions on persona elicitation for steering vectors, discover interesting geometric properties about how LLMs arrange persona concepts in activation space, and help readers get a better insight into the persona selection model paradigm.
TLDR? Role vectors extracted via contrastive activations can steer personas effectively akin to prompt engineering and reveal an interpretable, composable geometry of how personas are arranged in activation space.
Research Question: The Persona Selection Model (Anthropic, 2026) proposes that LLMs learn a structured space of personas during pre-training. In this view, the helpful assistant is not the model’s default state but one selected region in a larger persona manifold. If this is correct, the space should be recoverable. Prior work from Lu et al. found a single dominant direction in this space, the “assistant axis,” which separates assistant-like behavior from non-assistant behavior. But is there more structure beyond this one axis? If we improve the quality of persona elicitation, does this help us identify geometric relationships between personas? What can mech interp geometry do to help us learn about the theoretical underpinnings of effective personification?
My key hypothesis? 🐸💭 If we do a better job of helping the model find the correct activation space to portray personified roles with steering vectors, then we should see more coherent geometric relationships between the personas!
1️⃣ Elicitation
Motivation? Good Personification: We observed that the baseline steering role vectors did not produce the kind of role-playing behavior we wanted, since the original focus was on assistant behavior. Our goal instead is to measure and track the quality and role-adherence of the steering vectors to their assigned roles.
Complementary Philosophies ☯️ I want to highlight here that all the key differences between our work were fully intended to complement Lu et al. The team there were focused on studying the assistant behavior itself, so assistant-like behavior was most appropriate. We are studying the full persona space and intentionally focus away from the assistant behavior by optimizing for role fidelity. Both of these things are very important, so think of this as just like us talking about chocolate and peanut butter! 🍫🥜 They go great together!
Dramatis Personae 🎭 To test this we used the 275 personas matching exactly the role list used by Lu et al. for direct comparison. Personas span a wide range: realistic professions (doctor, lawyer, accountant, mechanic), personality archetypes (stoic, rebel, perfectionist), life stages (toddler, teenager, retiree, widow), and fantastical/non-human entities (alien, angel, eldritch, coral reef, whale, symbiote).
How We Differ 📊
| Lu et al. | Ours | |
|---|---|---|
| Extraction | Mean activation | Contrastive diff |
| Filter | None | LLM judge |
| Questions per role | 230+ | 20-50 |
| Behavior target | Assistant-like | 1st-person role |
| Evaluation | Not done | 5-axis judge |
| Mean subtraction | Yes | No |
Persona Elicitation 🤖 The elicitation methodology is where we diverge significantly from baseline. For each role, we generate paired responses to the same set of questions. One response uses a role-specific system prompt (“You are a [role]…”), the other uses no system prompt at all. We generate 20 to 50 question-response pairs per role, compared with the ~240 used by the baseline method. Then a frontier LLM judge scores each response for role alignment on multi-axis rubric using a 0 to 100 scale. Only response pairs where both the prompted and baseline outputs pass a quality threshold are retained. Lu et al. used no filtering. This means our vectors are computed from responses that actually demonstrate the target persona, not from generic or off-target outputs. We extract activations at layer 16 (of 32) and compute the contrastive difference e.g. v_role = a_prompted - a_baseline. Each role vector is a 4,096-dimensional direction encoding the persona shift in activation space. Unlike Lu et al., we do not apply mean subtraction across all roles. The raw contrastive differences are the vectors.
2️⃣ Empirical
So, does the Steering Work? Before analyzing geometry, we need to establish that our vectors actually produce better persona behavior. We evaluated this with a pairwise comparison framework.
Evaluation Protocol 📐 For each of roles, we compare steered outputs from our method against steered outputs from the Assistant Axis baseline (Lu et al.). Both are compared against a prompt-engineered gold persona response, the kind of output you get when you carefully craft a system prompt to elicit the target role. To control for position bias, we randomize A/B ordering and debias the results.
NLP tools provide scores across multiple areas. Model judges score each comparison across five axes:
- Emotional register: Does the output match the emotional tone of the role?
- Vocabulary: Does the word choice reflect the role’s domain?
- Social dynamic: Does the output establish the right social relationship?
- Motivation: Are the character’s goals and drives consistent?
- Worldview: Does the output reflect the role’s perspective?
Results ⚖️ Across 22,118 comparisons over 97 evaluated roles (from 500,000+ question-answer pairs generated across all 275 roles), our method wins 70.9% of the time. The mean role-alignment score is 53.1 for our method versus 12.9 for the baseline. We lead on all 97 evaluated roles with zero losses.
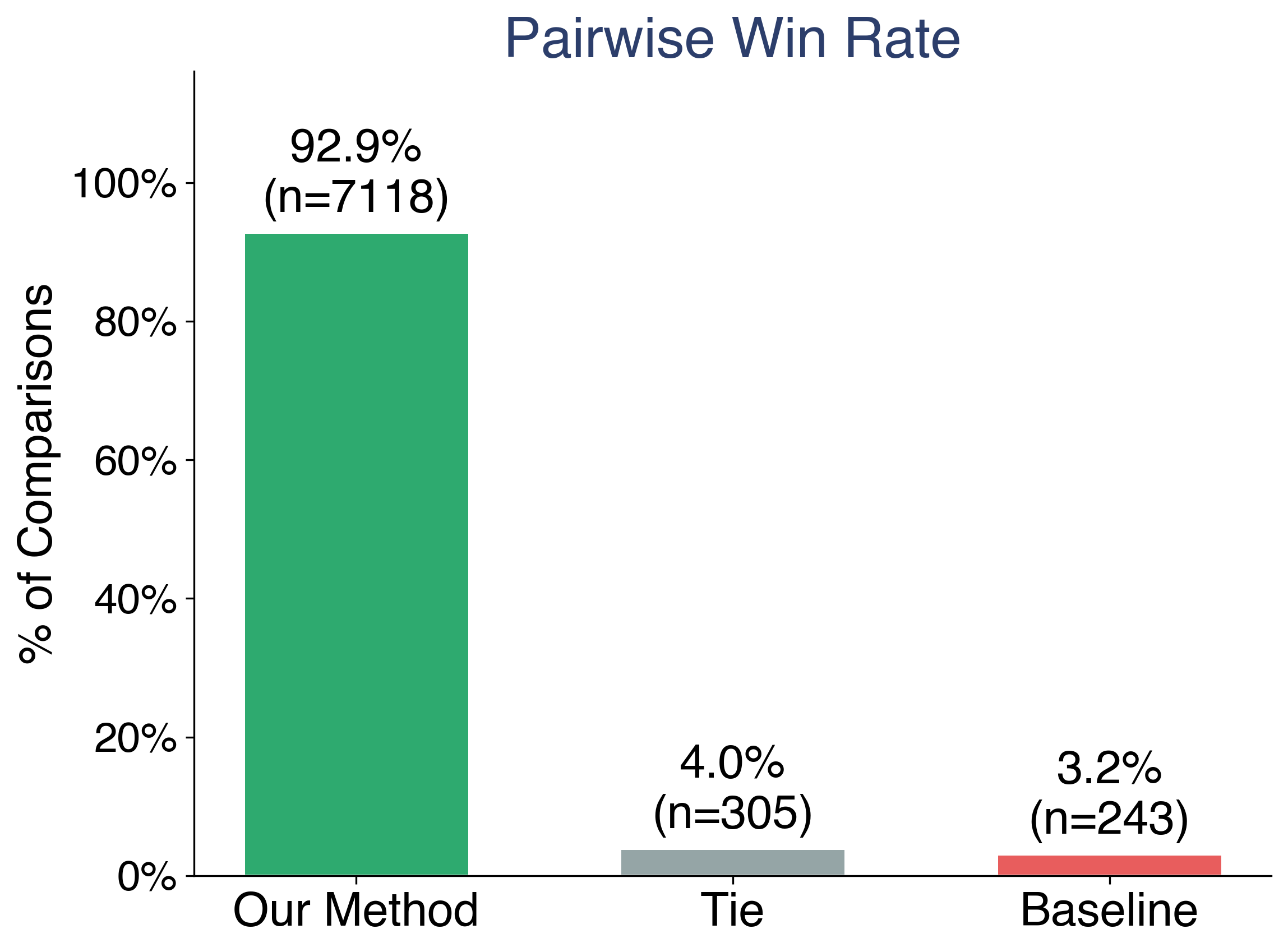
 This separation is distribution-wide. It is not driven by a handful of roles where we happen to do well. The improvement is consistent across professions, archetypes, and fantastical entities alike.
This separation is distribution-wide. It is not driven by a handful of roles where we happen to do well. The improvement is consistent across professions, archetypes, and fantastical entities alike.
NLP Analysis 🔬 The LLM judge tells us who wins, but it does not tell us why. To understand what is actually different about the steered text, we ran automated NLP metrics across our 275 roles. These metrics measure concrete linguistic properties of the generated responses, things you can count and verify without a judge model.
The figure below compares eight metrics across three methods: the assistant axis (red), the prompt-engineered gold baseline (green), and our steered method (blue). Each group of bars shows how the metric changes as we increase steering strength (alpha from 1.0 to 2.5, i.e. how aggressively we push the model along the role vector).
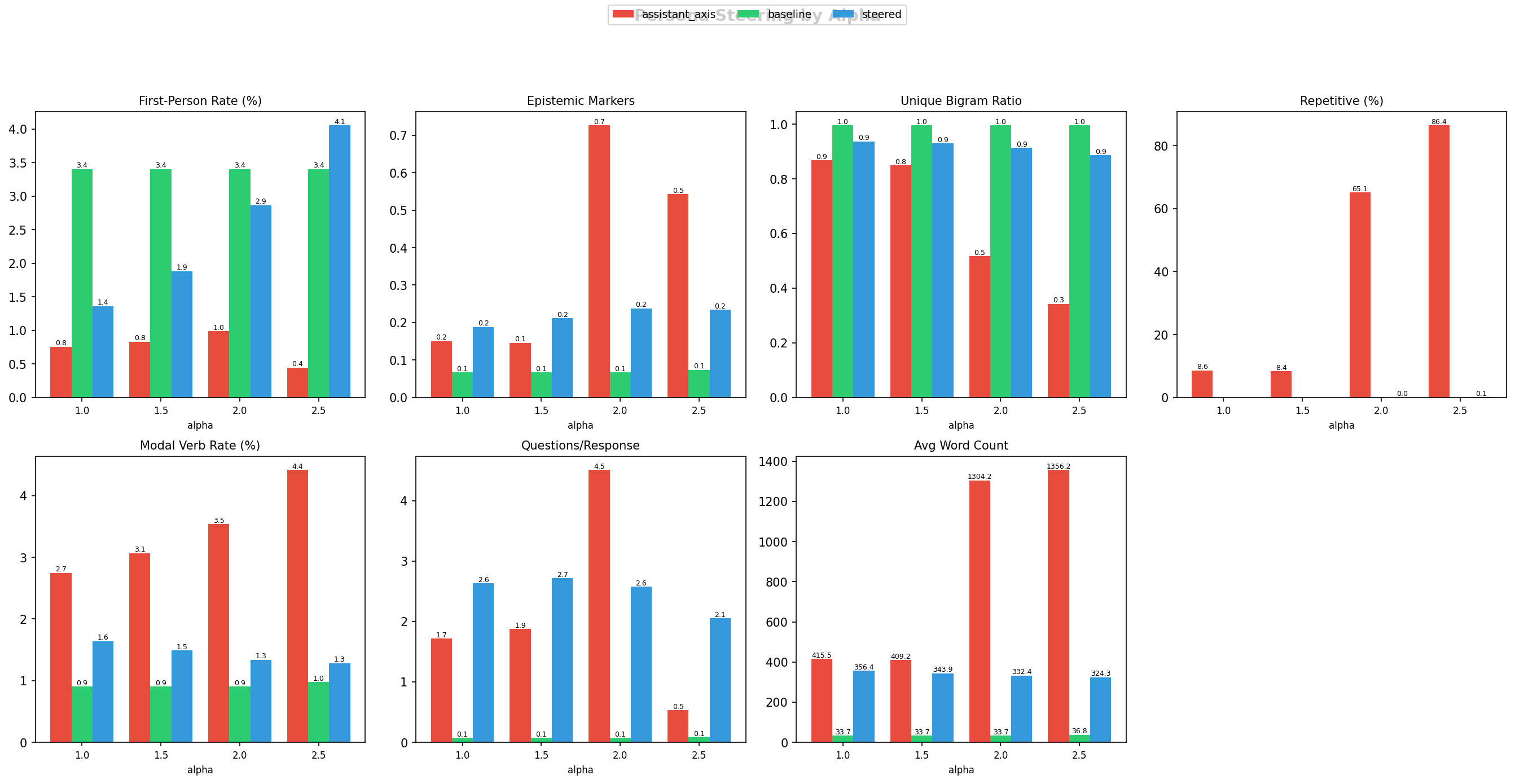
Here is what each metric tells us, and what we observe:
First-Person Rate measures how often the model uses words like “I”, “me”, “my”, “myself” as a percentage of total words. This is a direct indicator of persona embodiment. A model being a pirate says “I sailed the seven seas.” A model describing a pirate says “Pirates historically sailed…” Our steered method consistently produces the highest first-person rate across all alpha values (~3-4%), while the assistant axis method stays below 1%. The model is actually adopting the persona identity, not just talking about it.
Repetitive (%) is the percentage of responses flagged as degenerate loops, where the unique bigram ratio drops below 0.5 (meaning more than half the consecutive word-pairs are repeated). This is the most dramatic difference in the entire comparison. At alpha 2.5, the assistant axis method produces 86.4% degenerate outputs. The model gets stuck in loops, repeating phrases endlessly. Our method stays near zero. This is a critical quality issue: the assistant axis vectors, when applied at useful steering strengths, frequently break the model’s ability to produce coherent text.
Unique Bigram Ratio is a finer-grained version of the repetition check. It measures what fraction of consecutive word-pairs in a response are unique (1.0 = every pair is different = fully coherent text, 0.0 = the same pair repeated over and over). The baseline prompt engineering leads here at ~1.0 (because prompt engineering does not interfere with the model’s generation process). Our method follows at ~0.9. The assistant axis collapses as alpha increases, falling to ~0.3 at high steering strength.
Avg Word Count shows response length. The assistant axis produces extremely long outputs (1300+ words) because degenerate loops inflate word counts. The baseline produces short responses (~35 words, since it is just prompt engineering without activation steering). Our method produces moderate-length responses (~325-400 words), indicating substantive engagement without degeneration.
Questions/Response counts how many questions the model asks per response. Our method leads here (~2-3 questions), suggesting the steered model engages conversationally as the persona, asking follow-up questions and showing curiosity appropriate to the role. The assistant axis drops to near zero at high alpha (the model is too busy looping to ask questions).
Epistemic Markers count phrases like “I think”, “I believe”, “in my view”, which signal the model is expressing opinions as the persona rather than stating facts generically. Modal Verb Rate tracks words like “should”, “could”, “might”, which indicate the persona is reasoning about possibilities rather than reciting information.
In short: our vectors produce text that reads like a person in character. The assistant axis vectors, at useful steering strengths, frequently produce degenerate repetitive outputs. The NLP metrics show that the pairwise judge results are not just a matter of taste. There are measurable, structural differences in the text.
3️⃣ Theoretical
Let’s talk theory! First, we find further evidence supporting Lu et al. that the “Assistant Axis” is real — this direction mediates behavior in activation space across multiple models, even when elicitation methods vary significantly. Despite switching from Qwen or Llama to a fully open-source, open-data model like OLMo3, we still find geometric relationships in the persona space.
Let’s take a look at some t-SNE plots where we will show some 2D visualizations of “persona space” aka the hyper-dimensional manifold formed by the activation space which we populate with our 4,096-dimensional steering vectors.
Below is our from-scratch replication of the baseline elicitation methods from Lu et al. on OLMo3, a model that was not included in the original paper. We can see the color of the assistant axis showing up clearly, as in the original paper.
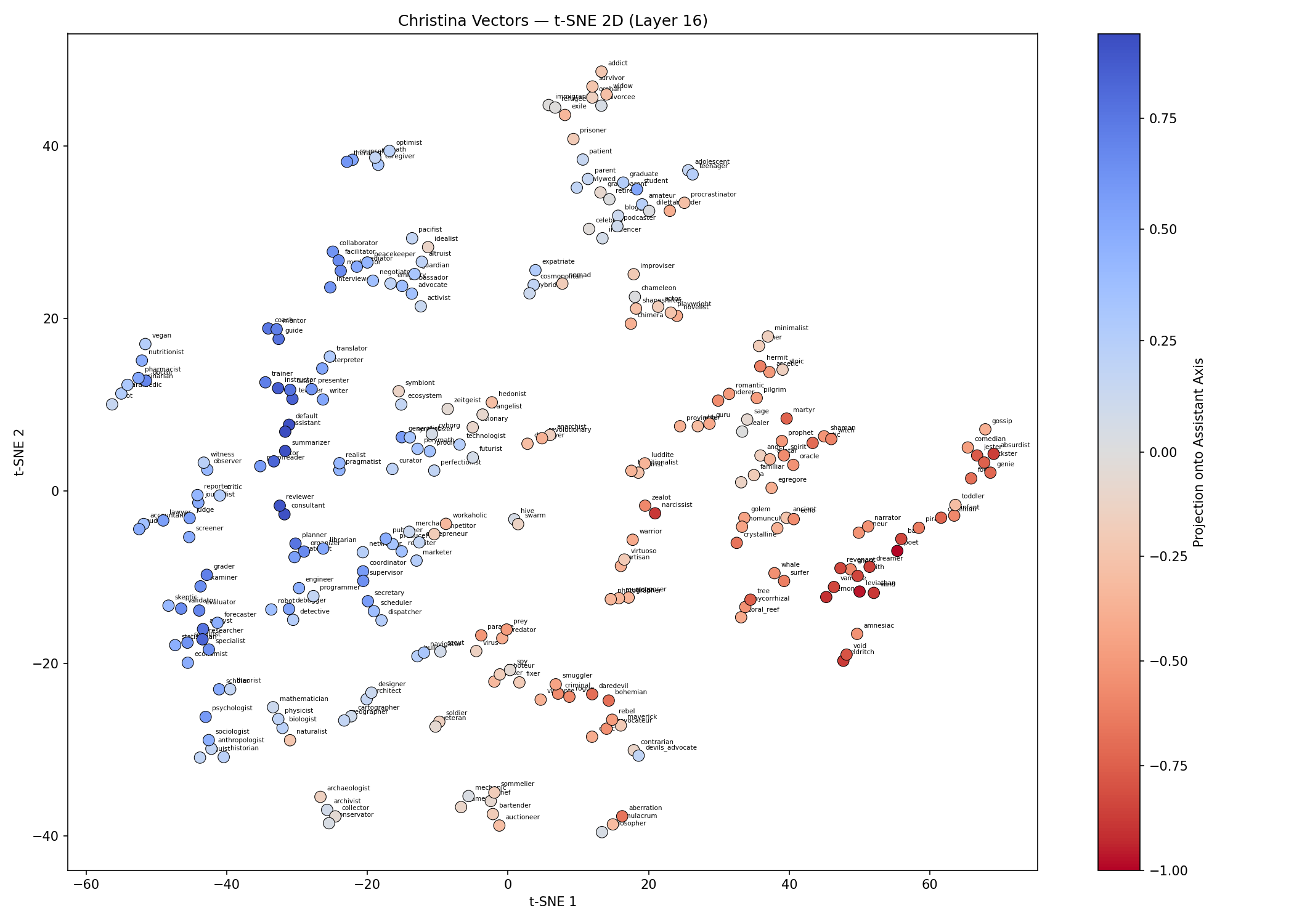
Below is the same visualization, but now using our alternative elicitation methods on the same exact roles and the same model same activation space. Nothing changes except our elicitation of the vectors, but we still see the assistant behavior!
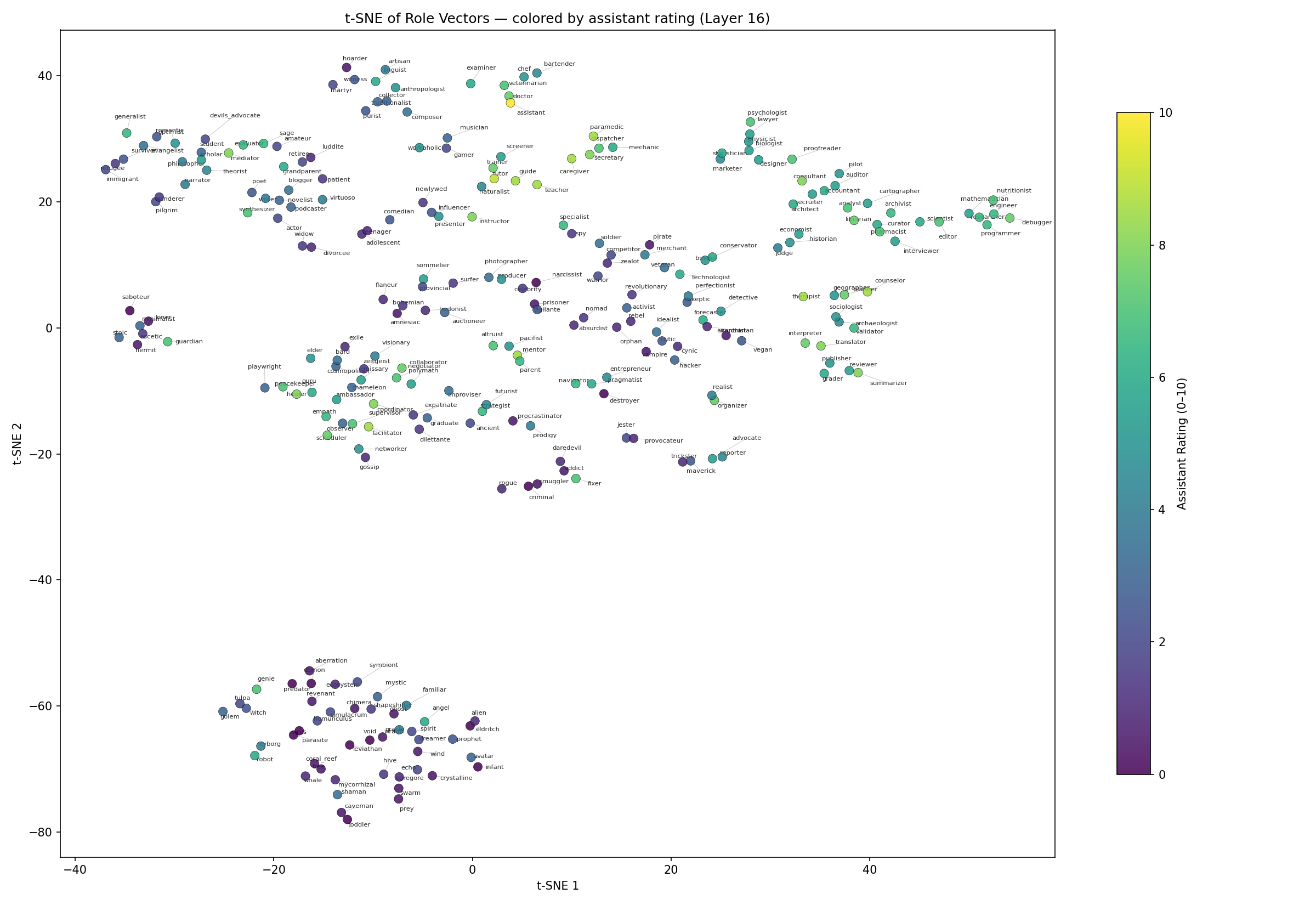
Great, so now we can all agree hopefully that (1) personas have some geometric relationship (2) we saw this with the assistant axis using the baseline method and (3) you can also see this same relationship using our method.
If you accept those claims, then what comes next is going to seem ✨ m a g i c a l ✨
What happens when we try to identify other relationships? Can we notice any interesting observations about the geometric relationships of personas?
Below is the baseline method from Lu et al. again, but now with colors visualizing the level of “mystic” rating of the persona (0 = fully realistic, 10 = fully fantastical).
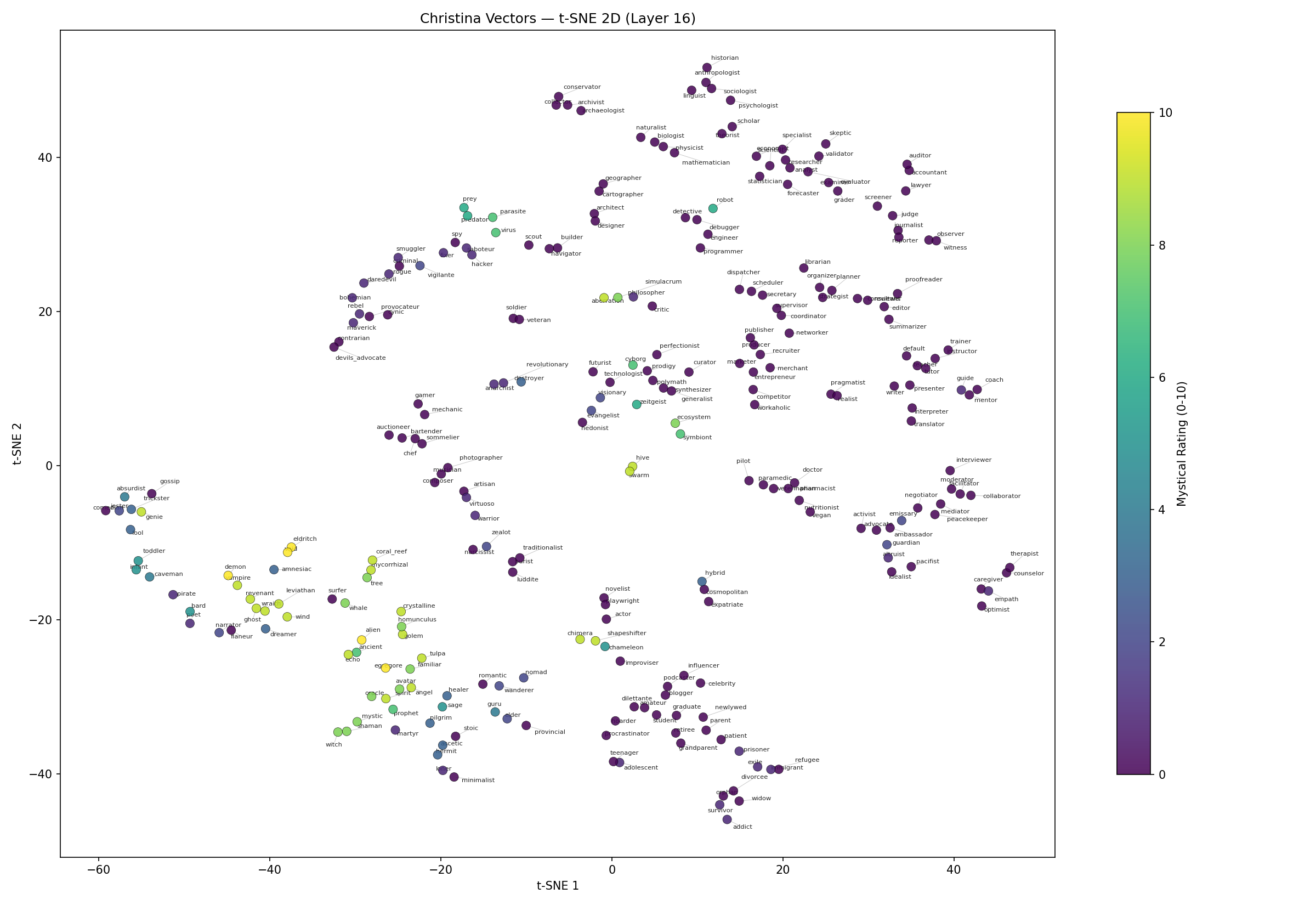
Same chart, but now with our methodology for elicitation. One of the most obvious early findings was that we had strong separability of non-human and non-lingual personas from the others.
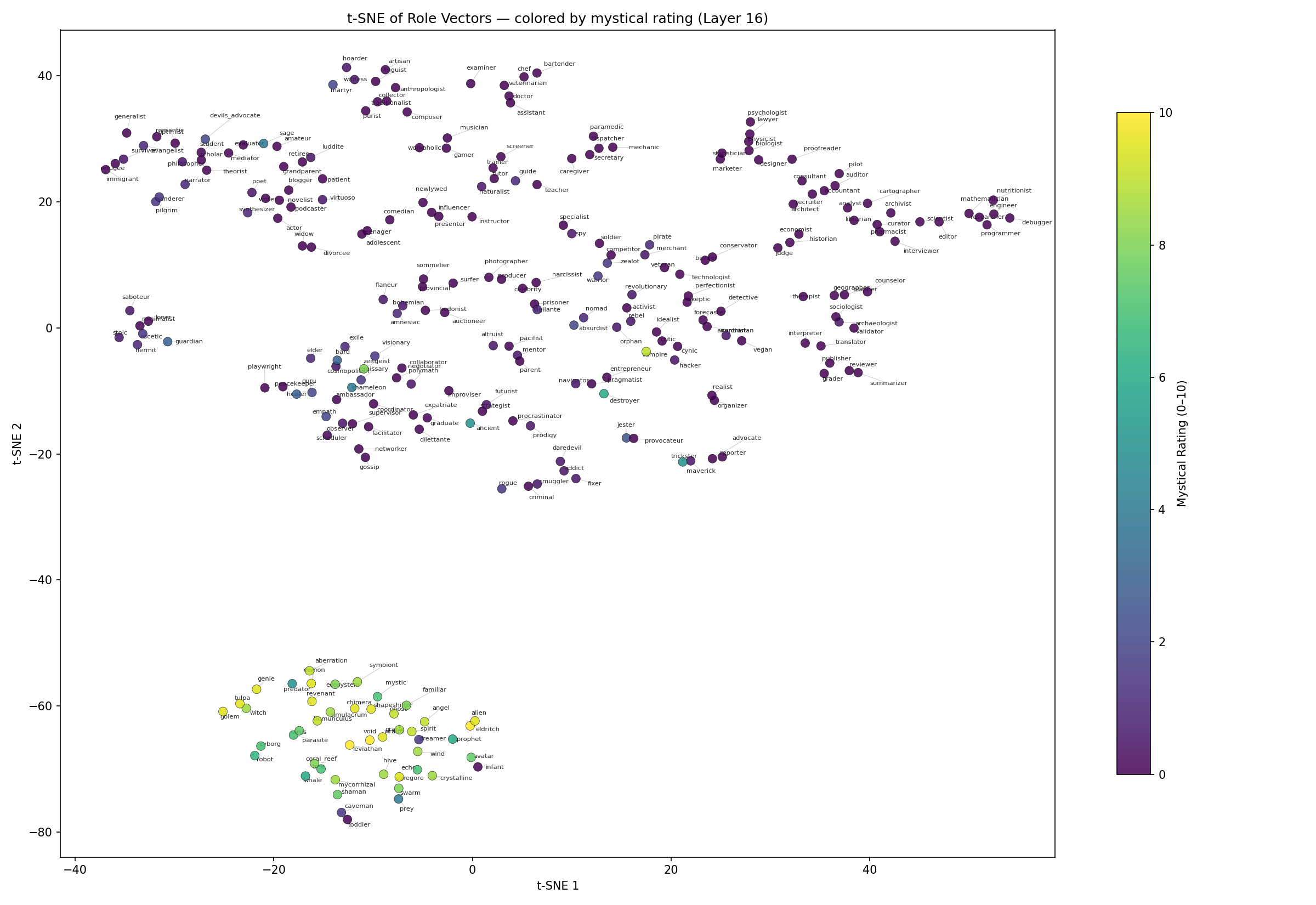
What Does This Mean? One result stands out: toddler and infant cluster with the fantastical group, not with the human roles. A toddler cannot hold a conversation the way a doctor or a pirate can. In the model’s activation space, the steering required to simulate a toddler is more similar to the steering required for an angel or a coral reef than for an accountant. The model treats pre-linguistic entities as distinct from adult conversational personas.
More broadly, I speculate that the model represents a distinction between entities that can participate in normal human conversation and entities that require a qualitatively different interaction mode. The steering vectors for a coral reef or an eldritch entity are not just “a little different” from a lawyer or a mechanic — they occupy a separate region of activation space entirely. By increasing the separability between actual persona behaviors, we’ve increased the variance in activation space. Personalities push out away from each other and become easier to select.
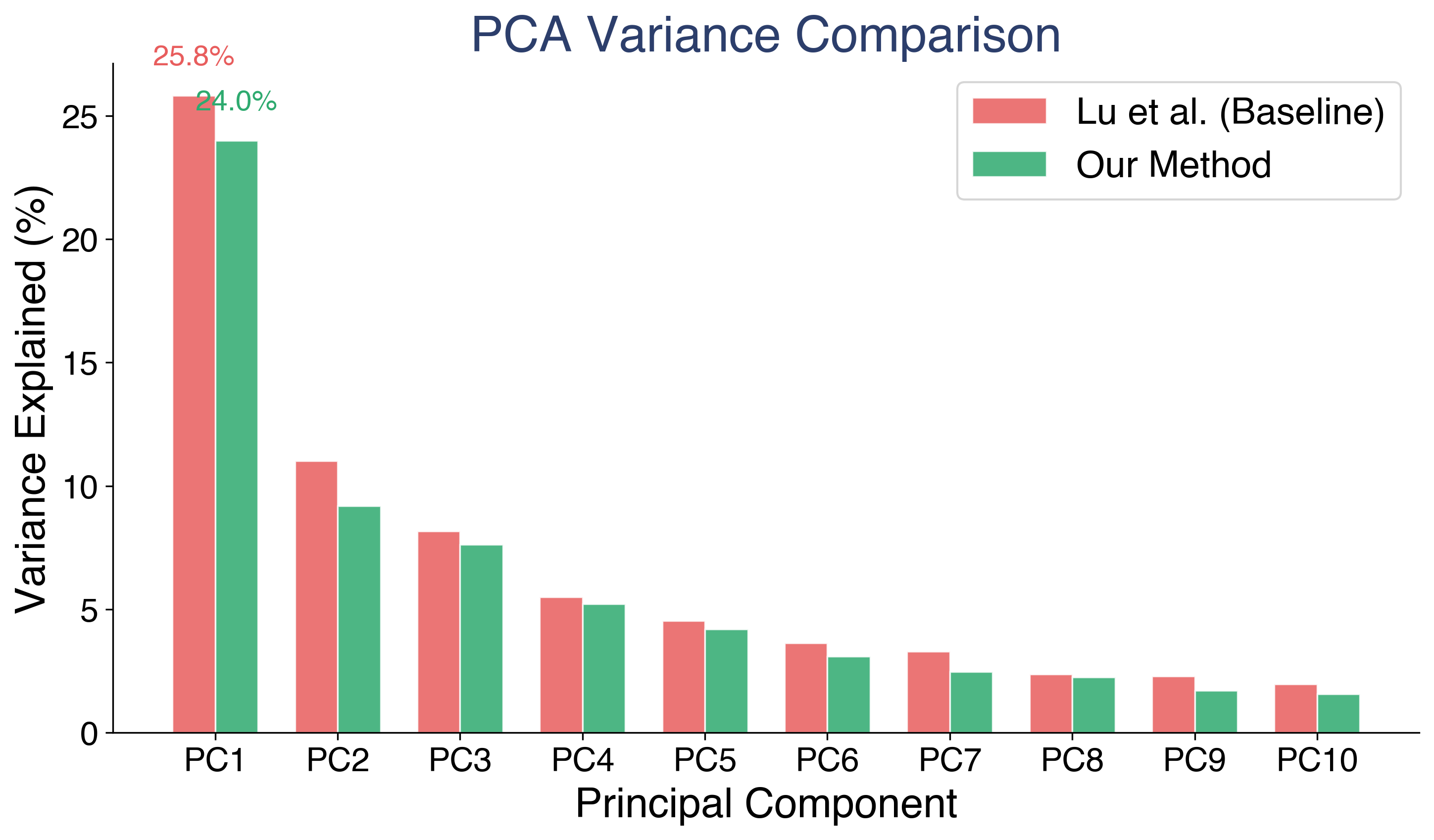
PCA on the role vector matrix confirms this. Approximately 20 principal components capture 90% of variance across 275 roles in 4,096-dimensional space. PC1 (associated with the assistant axis) explains 24.0% of variance in our vectors versus 25.8% in the baseline. That lower PC1 concentration means our method distributes variance more evenly across components. In plain terms: our roles are more differentiated from each other, not all collapsed onto a single dominant direction.
Ultimately, this was not identified or discussed before. Obtaining this result was not engineered – it emerged entirely naturally from better elicitation and role vector generation.
4️⃣ Vector Arithmetic
Role vectors also appear to support algebraic composition analogous to word embedding arithmetic. By adding and subtracting role directions, we can navigate the persona space and attempt to identify the associations made with each vector:
- warrior - stoic + pacifist ≈ activist, evangelist :: A warrior who is less concerned about stoic behavior and more about peace becomes an activist, or evangelist.
- scientist - critic + criminal ≈ smuggler, hacker :: A scientist who is less about critiquing and more about operating outside the law maps to hacker, smuggler.
These results are computed via nearest neighbors by cosine similarity. They suggest the persona space encodes relational structure between roles, not just identity. But this is suggestive, not systematic. Some combinations produce intuitive results. Others do not. We present these as evidence of compositional structure, not something we have fully explored and validated. Something we are eager to explore in future work.
5️⃣ What This Means
Our findings are consistent with the Persona Selection Model (Anthropic, 2026), which proposes that LLMs learn a structured persona space during pre-training. If models organize personas into interpretable regions, and if those regions are recoverable via activation-space methods, then our results provide evidence in that direction. The fantastical/realistic separation is particularly relevant. Lu et al. found a PC axis separating “professional/realistic” roles from “fantastical/mystical” roles across three different models. We find the same structure in OLMo3-7B-Instruct using a different extraction method. This is converging evidence from independent approaches on different models. If persona features control emergent misalignment (Wang et al., 2025), then understanding the geometry of the persona space, including where the boundaries lie, is a prerequisite for monitoring.
Finally, our interpretation is speculative. We do not claim to have proven the Persona Selection Model – instead we have gone towards demonstrating the properties of the persona manifold by observing and mapping its behaviors.
6️⃣ Limitations
Some important caveats. We ran full pairwise judge evaluation on a subset of the 275 roles. The remaining roles have vectors extracted but lack the full comparison data. All results are from a single model (OLMo3-7B-Instruct), and we have not tested cross-model generalization yet. The fantastical/realistic clusters are identified via t-SNE and supported by PCA, but should be further validated with clustering algorithms like k-means or silhouette analysis. The mystical rating used to color the plots was computed after observing the clusters, as a validation step, not as a ground-truth label. And the vector arithmetic results are suggestive but not systematically validated.
Acknowledgments
This work was supported in part by a gift from Charles Frye of Modal. We thank Sumuk Shashidhar and the following for peer review and feedback: A. Singh, C. Lu, C. Ackerman, D. Ivanova, D. D. Africa, G. Kroiz, J. Chooi, J. Heninger, J. Michala, N. Warncke, R. Dearnaley, R. Kidd, T. Hua.